阿里开源长文本深度思考模型!渐进式强化学习破解长文本训练难题
梦晨 发自 凹非寺量子位 | 公众号 QbitAI
推理大模型开卷新方向,阿里开源长文本深度思考模型QwenLong-L1,登上HuggingFace今日热门论文第二。
其32B参数版本超过OpenAI-o3-mini、Qwen3-235B-A22B等,取得与Claude-3.7-Sonnet-Thingking相当的性能。
除测评分数外,论文中还详细展示了一个金融文档推理的案例。传统模型容易被无关细节误导,而QwenLong-L1通过回溯和验证机制过滤干扰信息,正确整合关键数据。
任务要求:根据文档回答问题“将优先票据的发行成本与第一年的利息支出合并计算,总资本成本是多少?”
首先出场的基础模型DeepSeek-R1-Distill-Qwen-14B被文档中“自2011年10月15日起每半年支付一次利息”误导,根据不相关的时间和财务信息,错误计算了第一年的利息支付。
接下来,经过额外SFT的版本仍然未能解决这个问题。
它在对不相关文档进行过度分析的循环中自我怀疑,最终尽了最大生成限制(10000 tokens),却没有给出最终答案。
相比之下,虽然QwenLong-L1-14B最初也表现出类似的分心,但它很快进行了有效的自我反思。通过及时验证和回溯,成功过滤掉了不相关的细节,得出了正确答案。
那么,QwenLong-L1是如何做到的?
渐进式上下文扩展
首先,现有推理模型在面对长文本(如几万字甚至更长)时遇到什么问题?
Qwen团队通过对比实验发现,长文本推理的强化学习训练存在两个“硬伤”:
一是训练效率低,传统强化学习(RL)方法在长文本中容易陷入局部最优,奖励收敛慢,限制了策略优化时的探索行为。
二是优化过程不稳定,长文本任务的输出长度更高、输入长度分布不均匀,导致策略更新时的方差被放大,训练过程中参数更新不稳定(如KL散度坐过山车)。
为此团队提出QwenLong-L1训练框架,核心是通过渐进式上下文扩展让模型逐步适应长文本推理。训练过程分为两阶段:
预热监督微调(Warm-Up Supervised Fine-Tuning)
在开始强化学习之前,先用高质量的演示数据进行监督微调,让模型先具备基本的长文本理解能力、推理链生成能力和答案提取能力。
团队从DeepSeek-R1蒸馏了5.3K个高质量的问题-文档-答案三元组,确保模型有个稳定的起点。实验结果显示,这个”热身”阶段对后续的强化学习训练至关重要。
课程引导的分阶段强化学习(Curriculum-Guided Phased Reinforcement Learning)。
从短文本逐步过渡到长文本。例如,先训练模型处理2万token的文本,稳定后再增加到6万token,最后到128K。每个阶段只关注对应长度的文本。
此外还引入了难度感知的回溯采样机制。在进入下一阶段时,会保留前一阶段中最难的样本(平均准确率为零的那些),确保模型不会”忘记”如何处理困难案例。
长文本问答的答案往往比较开放,单纯的规则匹配太死板,可能漏掉正确答案。
QwenLong-L1在强化学习训练中采用混合奖励函数,结合了基于规则的验证和LLM-as-a-Judge。
规则验证也就是直接检查答案是否与标准答案完全一致(如数学题计算结果是否正确),再用另一个模型判断答案的语义是否正确(应对答案表述不同但意思一致的情况),两者结合避免单一规则过于严格或宽松
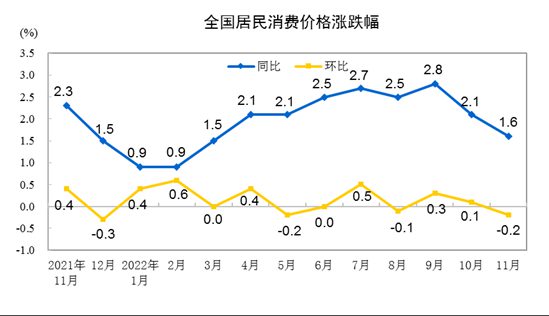
在DocMath、Frames、2WikimQA等七个长文本基准测试中,QwenLong-L1-14B相比基础模型R1-Distill-Qwen-14B,平均提升了4.1分,超越了Gemini-2.0-Flash-Thinking和Qwen3-32B。
QwenLong-L1的32B版本相比基础模型提升了5.1分,达到70.7的平均分。这个成绩不仅超过了OpenAI-o3-mini(70.4分)、Qwen3-235B-A22B(70.6分),甚至和Claude-3.7-Sonnet-Thinking(70.7分)打成平手。
团队还针对Test-time Scaling性能做了评估。当生成16个候选答案时,QwenLong-L1-14B的表现超过了DeepSeek-R1和OpenAI-o1-preview。
最后论文中还深入探讨了两个问题:
既然SFT相对简单便宜,为什么还要费劲搞强化学习(RL)?
实验结果很有启发性。长文本SFT确实能带来2.6分的提升,比短文本SFT的效果更好。但是,如果在长文本SFT的基础上再做RL,提升幅度只有0.3分;而在短文本SFT基础上做RL,却能提升3.2分。
对此团队提出一个观点:SFT提供了一种经济的性能提升方式,而RL则是达到最优性能必不可少的。
通过跟踪分析了四种关键推理行为发现3个结论:信息定位(grounding)、子目标设定(subgoal setting)、回溯(backtracking)和验证(verification)。
所有模型都展现出明显的推理行为,尤其是信息定位行为出现频率最高,这证明了它在处理上下文依赖推理时的重要性;强化学习训练过程中,这些行为会逐渐增强,并与性能提升高度相关,表明强化学习能有效调整输出空间,优先保留有助于得出准确解答的推理模式虽然SFT模型也能学会这些行为,但这些表面上的行为模仿并没有带来实质性能提升,这揭示了SFT更关注表面模式匹配,而非实质推理能力的培养。
论文地址:https://arxiv.org/pdf/2505.17667
Free HD XXXX Tube HD
美女被❌脱脱内内做运动中国人
绝区零艾莲裸体无码照片
魔女伊蕾娜怀孕大肚子
俄罗斯A级毛片BBBBB
小心🐤戳进老师🍑里面动漫
调教婬奴女警花H文
日本精品裸体奶头大胸av主播
Lisa❌❌裸体热舞
久久人妻少妇嫩草AV蜜桃漫画
斗罗之乱婬h侵犯朱竹清
大片黄冈站
chara乳液狂飙翻白眼流口水
qztv2.app
动漫❌裸体❌女同❌2D照
露半球露到奶头
成全免费高清在线观看第5季预告
赵一曼被C到高潮下不了床
女性私密粉嫩部位
小医仙被爆❌3D在线观看
女厕美女撒尿㊙️视频
男的用🍌放进女的🍑
小宵虎南全集免费观看
直男爆c小受疼哭了🔞
动漫裸体㊙️视频免费
阮梅涩涩同人❤️网站
豆花已满18禁免费进入
先掀开内裤边躁狠狠躁漫画
刘晓庆一级毛片全身裸体下载免费
Naruto❌Sakura钢手
㊙️羞羞漫画在线入口
91❤口爆吞精合集国产
纲手被❌❌吸乳羞羞动漫
章若楠被吸乳❌❌羞羞
奇优影院电视剧在线高清免费观看
涩涩视频国产AV一女战两男
原神申鹤口球捆绑紧缚图
迪丽热巴裸体㊙️无遮
把校花🌸吊起来揉搓双乳
ceкес欧洲видео⚡️
порнов1080p1080p2019年
女人自慰免费观看
憋尿失禁控制排泄憋尿小作文
青色大脑手机版下载
亚洲另类⭕⭕⭕⭕XXXX97
老汉趴在嫩妇身上耕耘
亚洲AV第二区国产精品
动漫又爽❌又黄❌雏田
高中校花被cao到爽哭视频
51在线无码精品㊙️入口九色
日本老熟妇XXⅩ日本老妇om
HD-AudioGeneric
裸乳r18mmd弱音自慰发现被啪
风流老太婆做受视频
老师你奶好大摸起来好爽视频
神里绫华白丝好紧我进去了
黄瓜视频app永久免费下载
美女cos被爆❌羞羞视频
秦守仁大战孟秋兰78集剧情简介
中国老头老太❌❌❌
把🍌伸进女人的🍑做运动国产
3b不知火舞被❌到爽喷水
老师GayGays✅免费自慰
浪货今天就把你🌿到服为止小说
免费无遮挡🔞网站在线观看
老头老太做爰视频播放
免费添女人囗交做爰视频
免费无遮挡🔞动漫网站下载
美女警察开腿让我爽一夜
美女裸体㊙️扒开腿挤乳免费
农村老太HD肉HD
被到爽流片依人明星
黑客家庭破解在线观看免费版
陈丽佳专辑《玉》1
性中国❌❌潮喷偷拍
18🈲🍆🍑无套直蓝莓
边添小泬边狠狠躁视频网站动漫
中国🇨🇳老头性HD
宝可梦❌18禁漫画同人
把手伸胡桃的www
刻晴被到爽高潮痉挛动漫
网友评论 查看所有评论>>